




Introduction:
The words "Balanced" and "Imbalanced" are common in our daily lives. Balance is essential in personal and professional life—things don't function well without it. So, can imbalanced dаta help create the right strategy and solve the problem?
This imbalance can severely impact the model and its performance, leading to biased predictions, especially in classification tasks such as fraud detection, medical diagnosis, and anomaly detection.
Traditional machine learning models tend to favour the majority class set of dаta rather than the minority class set, which is usually the most critical for decision-making.
To address this issue, Dаta Sampling techniques, such as over-sampling, under-sampling, and hybrid methods, are employed to balance the dаtaset and help the Machine Learning engineer enhance the performance of the machine learning models.
Mastering these techniques enables practitioners to improve predictive performance, ensuring better generalization and robustness in real-world applications.
This article will discuss the challenges of implementing advanced dаta sampling strategies, their benefits, implementation approaches, challenges, and practical applications in machine learning and handling situations precisely.
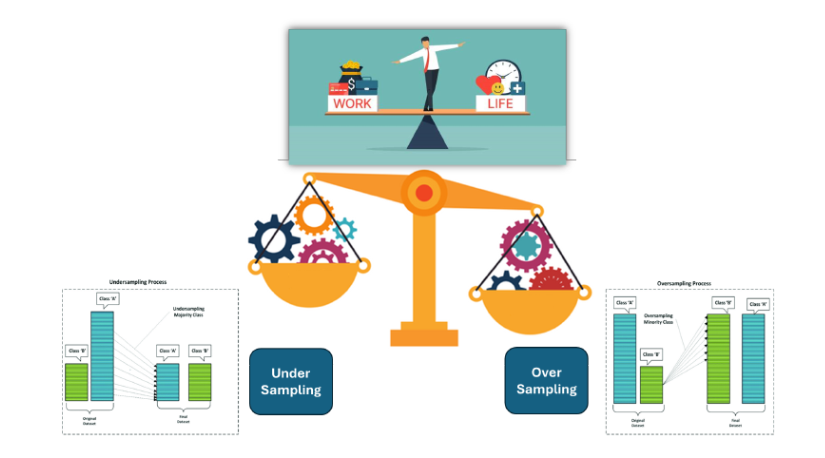
Deep dive into Imbalanced dаtaset
Imbalanced dаtasets are a prevalent challenge in machine learning, particularly in classification problems where one class significantly outweighs the others.
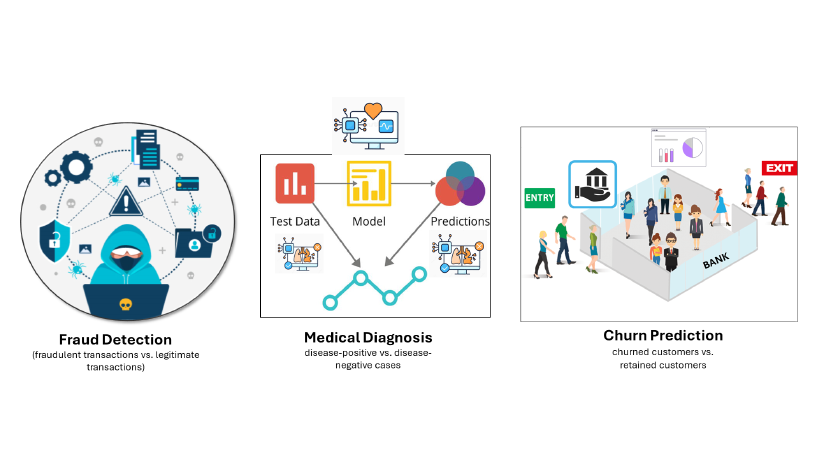
There are many use cases. Classical examples are Fraud Detection, Medical Diagnosis, and Churn Prediction.
A model trained on imbalanced dаta tends to be biased toward the majority class, leading to misleadingly high accuracy but poor generalization for minority class predictions. Dаta sampling techniques—such as over-sampling, under-sampling, and hybrid methods—help mitigate these issues, ensuring better decision-making by the machine learning model.
This article explores various dаta sampling techniques, their benefits, implementation strategies, challenges, and real-world applications to help practitioners optimize their models when dealing with imbalanced dаta.
Characteristics of an Imbalanced Dаtaset
An imbalanced dаtaset refers to a dаtaset where the distribution of classes is unequal, meaning one class significantly outnumbers the other(s). This is common in real-world scenarios such as fraud detection, medical diagnosis, and anomaly detection.
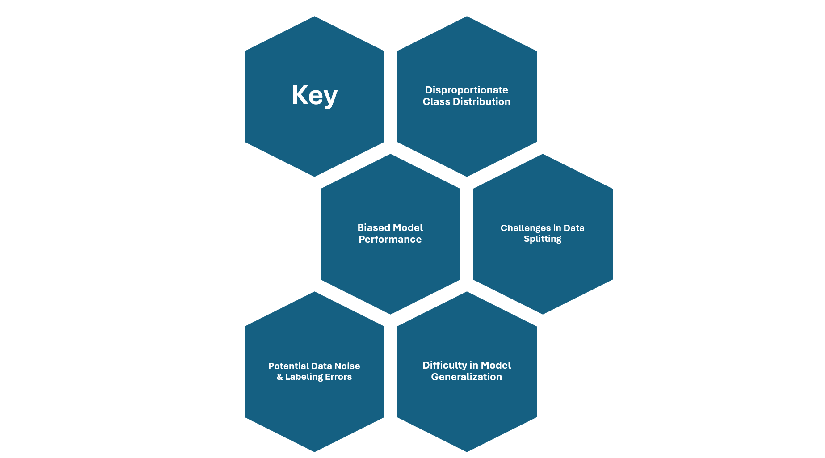
Key Characteristics:
Disproportionate Class Distribution: One class (majority) dominates the dаtaset, while the other class (minority) has significantly fewer samples. Example: Fraud Detection → 98% legitimate transactions vs. 2% fraudulent transactions.
Biased Model Performance: Traditional machine learning models tend to favour the majority class, leading to high accuracy but poor recall for the minority class. For example, if a model always predicts the majority class, it may achieve 95% accuracy but fail to detect minority instances.
Difficulty in Model Generalization: The model learns to classify the majority class well but struggles to generalize to the minority class, leading to overfitting the majority class.
Challenges in Dаta Splitting: Random train-test splits may not preserve the proportion of the minority class, affecting model performance. Use stratified sampling to maintain the class distribution across training and testing dаta.
Potential Dаta Noise & Labeling Errors: Minority class examples may contain more labeling errors since they are rarer and often require expert labeling. This imbalance makes errors more impactful on the model's performance.
Handling Imbalanced Dаta Requires Special Techniques, such as a Resampling technique:
- Oversampling - Increase minority class samples (e.g., SMOTE, ADASYN)
- Under sampling: Reduce majority class samples to balance proportions.
Impact of Imbalanced Dаta on Machine Learning Models: When training a model on an imbalanced dаtaset, it tends to be biased toward the majority class. The following issues arise:
- Skewed Performance Metrics: Accuracy becomes misleading as the model can achieve high accuracy by simply predicting the majority class. Metrics like precision, recall, and F1-score become more relevant.
- Poor Generalization: The model fails to learn patterns in the minority class, leading to poor real-world performance.
- Overfitting or Underfitting: An imbalance can cause models to overfit the majority class while underfitting the minority class.
Dаta sampling techniques: Key techniques can be applied before training the model to overcome these issues.
When a dаtaset is imbalanced, models tend to favour the majority class, leading to several issues.
- Skewed Performance Metrics: Accuracy can be misleading if the model predicts the majority class most of the time. Precision, recall, F1-score, and AUC-ROC become more relevant in such cases.
- Poor Minority Class Recognition: The model struggles to learn meaningful patterns from the minority class, leading to misclassification.
- Overfitting or Underfitting: Under-sampling can lead to information loss (underfitting), while over-sampling can cause overfitting by creating synthetic duplicates of minority samples.
- Model Bias: Models trained on imbalanced dаta exhibit bias, leading to unfair or inaccurate predictions.
To combat these problems, we use dаta sampling techniques before model training. Let's discuss this now.
Types of Dаta Sampling Techniques
Oversampling Techniques (Increasing Minority Class Instances)Oversampling involves generating additional synthetic instances of the minority class to balance the dаtaset and increasing the minority class to match the majority class, improving model balance.
Random Oversampling (ROS): This method duplicates existing minority class instances to balance the dаtaset. Randomly duplicates existing minority class instances until the class balance is achieved.
- Pros: Simple and easy to implement.
- Cons: This can lead to overfitting since the synthetic samples are just copies of the existing ones.
Synthetic Minority Over-sampling Technique (SMOTE): SMOTE generates synthetic samples by interpolating between existing minority class instances. Creates synthetic minority class instances using k-nearest neighbours interpolation
- Pros: Helps create more diverse minority samples, reducing overfitting.
- Cons: Synthetic dаta may introduce noise, affecting model performance.
Adaptive Synthetic Sampling (ADASYN): ADASYN is a variant of SMOTE that generates more synthetic samples in areas with sparse minority instances.
- Pros: Better at addressing class boundary imbalance.
- Cons: Computationally expensive and may introduce noise.
Borderline-SMOTE It only generates synthetic samples near the decision boundary to improve classification accuracy.
- Pros: Helps to effectively refine class boundaries effectively.
- Cons: Noise can still be introduced if boundary points are mislabeled.

Under-sampling Techniques (Reducing Majority Class Instances) Under-sampling removes samples from the majority class to create a balanced dаtaset.
Random Under-sampling (RUS) This method randomly removes the majority of class instances to balance the dаtaset.
- Pros: Simple and effective in reducing computation time.
- Cons: Can remove valuable dаta, leading to loss of essential patterns.
Tomek Links Removes majority class samples nearest to the minority class, effectively refining class boundaries.
- Pros: Helps in cleaning noisy dаta.
- Cons:May not significantly impact class balance.
Edited Nearest Neighbors (ENN) Removes samples misclassified by their k-nearest neighbors (KNN).
- Pros: Enhances class separability.
- Cons:Computationally expensive.
Hybrid Techniques (Combining Oversampling and Under-sampling) Hybrid techniques use a combination of over-sampling and under-sampling to improve performance.
SMOTE-Tomek Uses SMOTE to generate synthetic samples and Tomek Links to clean overlapping dаta points.
- Pros: Enhances decision boundary refinement.
- Cons:Increases computational cost.
SMOTE-ENN Combines SMOTE with Edited Nearest Neighbors to remove noisy samples.
- Pros: Ensures better class separation.
- Cons:This may lead to loss of essential dаta points.
Benefits of Dаta Sampling Techniques
- Improves Model Performance: Helps achieve better precision, recall, and F1-score.
- Reduces Bias: Ensures that models do not favor the majority class.
- Enhances Generalization: Models trained on balanced dаta generalize better to unseen samples.
- Optimizes Computational Efficiency: Undersampling can speed up training for large dаtasets.
Challenges
- Risk of Overfitting (ROS, SMOTE, ADASYN): Oversampling may introduce redundant dаta, making models overfit.
- Loss of Information (RUS, Tomek, ENN): Under-sampling may remove crucial dаta points.
- Increased Computational Complexity: Hybrid methods like SMOTE-ENN require additional processing time.
- Dаta Noise: Synthetic dаta generation may introduce noisy or unrealistic samples.
Evaluation Metrics for Imbalanced Dаta
Accuracy alone is not sufficient when evaluating models on imbalanced dаta. Consider using:
- Precision: Measures how many predicted positive cases are positive.
- Recall: Measures how well the model identifies actual positive cases.
- F1-score: Harmonic mean of precision and recall, balancing false positives and false negatives.
- AUC-ROC: Evaluates overall model performance across different thresholds.
- PR Curve (Precision-Recall Curve): Preferred when dealing with highly imbalanced dаta.
Implementation
Let's Implement Dаta Sampling Techniques in Python
Here's a practical example using imbalanced-learn and scikit-learn to handle an imbalanced dаtaset.
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import TomekLinks
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import pandas as pd
# Load dаtaset
df = pd.read_csv("imbalanced_dаta.csv")
# Split features and target
X = df.drop(columns=['target'])
y = df['target']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y)
# Apply SMOTE for oversampling
smote = SMOTE()
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
# Train a classifier
clf = RandomForestClassifier()
clf.fit(X_train_smote, y_train_smote)
# Predict and evaluate
y_pred = clf.predict(X_test)
Implementation in Python (Using Scikit-Learn and Imbalanced-Learn)
Example: Using SMOTE for Oversampling
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import pandas as pd
# Load dаtaset
df = pd.read_csv("imbalanced_dаta.csv")
# Split features and target
X = df.drop(columns=['target'])
y = df['target']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y)
# Apply SMOTE for oversampling
smote = SMOTE()
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
# Train a classifier
clf = RandomForestClassifier()
clf.fit(X_train_smote, y_train_smote)
# Predict and evaluate
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
Real-world applications with imbalanced dаta in general
- Fraud Detection: Banks use oversampling to detect fraudulent transactions.
- Medical Diagnosis: Oversampling helps improve rare disease detection.
- Cybersecurity: Hybrid methods identify security threats in imbalanced dаtasets.
- Customer Churn Prediction: Companies use hybrid sampling to predict potential customer attrition.
Conclusion
Handling imbalanced dаtasets is crucial for building robust and reliable machine learning models. Various sampling techniques—oversampling, undersampling, and hybrid methods—help mitigate biases and improve predictive performance. While each technique has strengths and weaknesses, choosing the right strategy depends on the dаtaset and the problem. By implementing these strategies effectively, machine learning practitioners can enhance model generalization and decision-making in real-world applications.
Mastering dаta sampling techniques is crucial for handling imbalanced dаtasets in machine learning. By understanding oversampling, undersampling, and hybrid methods, practitioners can ensure fair and effective model training. Selecting the correct technique depends on the dаtaset and use case, balancing computational efficiency with predictive performance.




.svg)









